

When I was perusing my LinkedIn feed the other day, I came across this thread about using SELECT *. In one of the replies, Aaron Cutshall noted that: “Another real performance killer is SELECT DISTINCT especially when combined with UNION. I have a whole list of commonly used hidden performance killers!”
To which started my brain thinking… What does happen when you use these together? And when you use UNION on a set with non-distinct rows, what happens. So for the next few hours I started writing.
UNION and DISTINCT
You probably know what they are, I know I do. BUT just for clarification, I figured I should make sure. (About half of my professional life is verifying than I actually know what are actually pretty basic concepts. It makes me a really good editor, and it keeps me from talking like a know it all!)
From the Microsoft documentation on set operators: UNION is a set operator that:
“Concatenates the results of two queries into a single result set. You control whether the result set includes duplicate rows:
UNION ALL– Includes duplicates.UNION– Excludes duplicates.”
That checks with my knowledge.
DISTINCT is a modifier that “specifies that only unique rows can appear in the result set. Null values are considered equal for the purposes of the DISTINCT keyword.”
Never completely happy with that NULL business, but it has always been that way.
Why would you use them together?
Why indeed? I realized at this point that I am violating one of my primary tenets of writing. Don’t start writing until you know the code works. I can’t tell you how many times that has bitten me.
But in this case, the goal here is basically a bit of a quiz. I want to be honest about my knowledge, and my limitations. Like I noted, if I am not sure sure, I will usually check or test my work. So my question is:
If you have two sets of data, where at least one set include data, and that data includes duplicates. What will UNION do? and then why would you combine that with DISTINCT?
So lets see what we can figure out.
First Test: UNION and DISTINCT
Say you have the following sets of data (The table create scripts are in the Appendix of this article, but it is just a simple table with one column (Value) and no constraints):
|
1 2 3 4 5 |
USE Tempdb; GO TRUNCATE TABLE TableA; TRUNCATE TABLE TableB; INSERT INTO TableA VALUES(1),(2),(3),(4); INSERT INTO TableB VALUES (2),(3),(4),(5); |
Now, lets UNION these two sets together:
|
1 2 3 4 5 |
SELECT Value FROM TableA UNION SELECT Value FROM TableB; |
This returns:
|
1 2 3 4 5 6 7 |
Value ----------- 1 2 3 4 5 |
As expected. What about the plan?
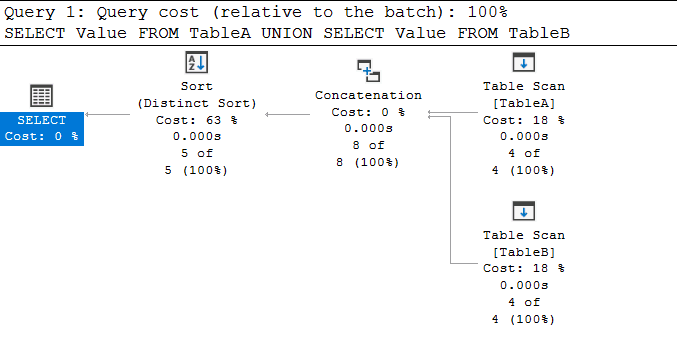
Pretty straightforward. Does table scans of each table, concatenates the two outputs, and then sorts the data and removed dups with a Distinct Sort (Sort) operator.
At this point in the process, I think I begin to understand Aaron’s concerns. Because if you are using them both in a query, then you wouldn’t likely be putting the DISTINCT operator on both sets, rather it is going on the individual queries. Something like this:
|
1 2 3 4 5 |
SELECT DISTINCT Value FROM TableA UNION SELECT DISTINCT Value FROM TableB; |
Either one or both, and the optimizer doesn’t change that output of the query (might change the performance, of course). So, while you obviously get the same result, you get a different plan:
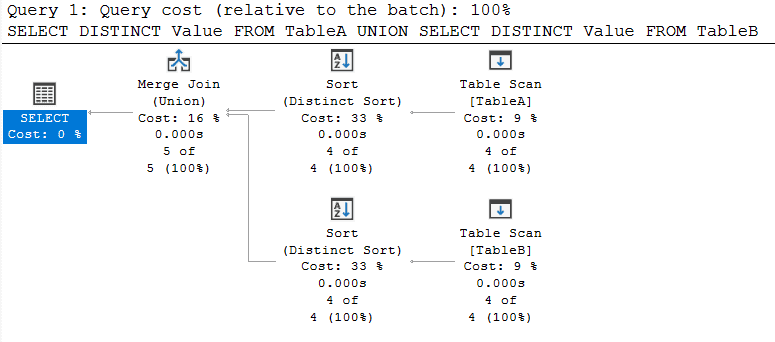
This time, it fetches all the data again with Table Scan operators, deduplicates the data using the Distinct Sort (Sort) and then merges the data with a Merge Join. Interestingly, instead of doing the distinct in a sort now, it does know that it has two sorted inputs so it can do the deduplification easier with a Union (Merge Join) that tosses out duplicates.
Finally, what will it do if you add the DISTINCT on the output from the UNION by using a CTE to perform the original query?
|
1 2 3 4 5 6 7 8 |
With BaseRows AS ( SELECT Value FROM TableA UNION SELECT Value FROM TableB) SELECT DISTINCT * FROM BaseRows; |
Of course, the same output, but we are back to the same plan as we started with. The optimizer realizes that the DISTINCT is superflous in this case and tosses out second DISTINCT. Sadly, there is no compiler warning that says: Warning: Silly superfluous DISTINCT used.
Second Test: UNION and Duplicated Data from One Side
Now the more interesting case to me that sort of goes outside of the DISTINCT and UNION experiment. What if one input has the duplicated data? I will reload the data like this:
|
1 2 |
TRUNCATE TABLE TableA; TRUNCATE TABLE TableB; INSERT INTO TableA VALUES (1),(1),(1),(1),(2),(3),(4),(5); |
Now only one table has data, and there are definitely duplicates. What will happen when this is executed?
|
1 2 3 4 5 |
SELECT DISTINCT Value FROM TableA UNION SELECT DISTINCT Value FROM TableB; |
Pretty obviously the same output as before:
|
1 2 3 4 5 6 7 |
Value ----------- 1 2 3 4 5 |
The duplicates are removed in the initial queries, so the first query returns 1,2,3,4,5, and unioning that to the empty set doesn’t change that..
But what about this?
|
1 2 3 4 5 |
SELECT Value FROM TableA UNION SELECT Value FROM TableB; |
Honesty point: As I am writing this, I am still in “I think I know what is going to happen, but not 100% sure” mode. Why don’t I clearly know this? Honestly, it is kind of rare to work with UNION, because most data will have no duplicates. And 99% of the time, duplicates in your sets mean there are issues. It is why a good data programmer is not a big fan of seeing DISTINCT in code without a 100 word essay in the comments. It most often masks issues with your code.
Thinking back to our previous query plan for this query, it scans the data, it concatenates the rows, then does a Distinct Sort. Which strongly indicates that we will get the same set of data, because I think the UNION operator will not only remove duplicates from the set operation, but also from either set.
And the only time it used a Union (Merge Join) was when it knew it had sorted and distinct data. Much like if these sets had primary keys\unique indexes that it could trust.
So I will now guess, that the output of the simple UNION query will be the same, 5 rows, with values 1,2,3,4,5 for each row.
Which it is. So I learned something, and I hope you did as well. UNION returns a distinct set of data, no matter if the duplication is from rows in each input, or only just the one.
Third Test: Crank up the number of rows
Since I am here and interested. What if I loaded a load of rows into the table. Maybe 100000 each? I will put back these rows. Will it change how rows are processed? Will performance change?
|
1 2 3 |
TRUNCATE TABLE TableA; TRUNCATE TABLE TableB; INSERT INTO TableA VALUES(1),(2),(3),(4); INSERT INTO TableB VALUES (2),(3),(4),(5); |
But now I will add 100,000 sequential rows into each.
|
1 2 3 4 5 6 |
INSERT INTO TableA SELECT value FROM Generate_Series(6,100006); INSERT INTO TableB SELECT value FROM Generate_Series(6,100006); |
It should be clear that there will be loads of duplicates in these sets. Now I am going to run the same queries again. I will also turn on STATISTICS IO and TIME to see if they perform differently.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SET STATISTICS IO,TIME ON; SELECT Value FROM TableA UNION SELECT Value FROM TableB; SELECT DISTINCT Value FROM TableA UNION SELECT DISTINCT Value FROM TableB; SET STATISTICS IO, TIME OFF; |
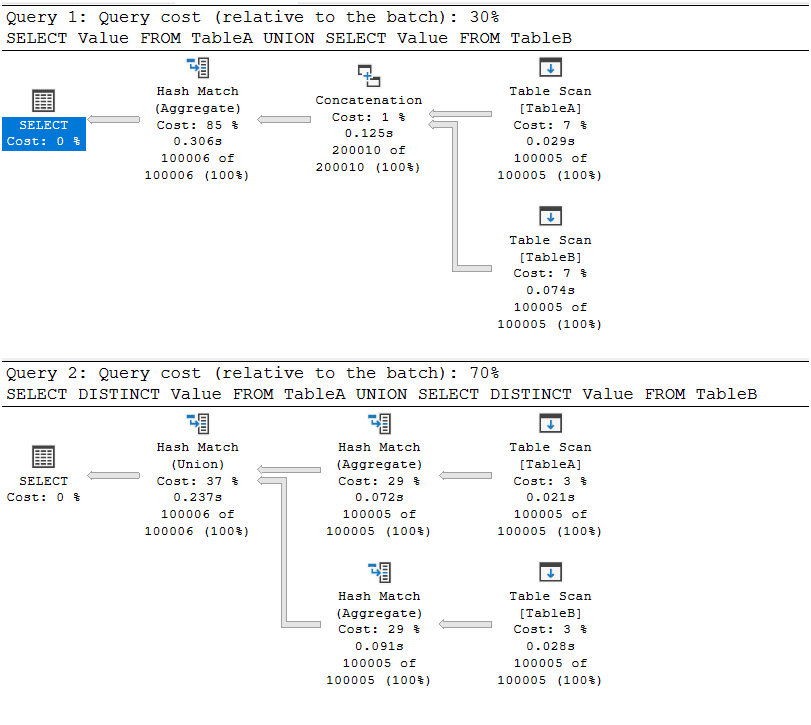
You should get a lot of rows back, 200012 to be exact. They will likely be sorted different in the output, due to the differences in how they are being processed. I tried this on Express Edition and Developer Edition. In the first image is the Express output, and the Developer Edition used parallelism.
Express Edition, No Parallelism:
Developer Edition, With Parallelism:
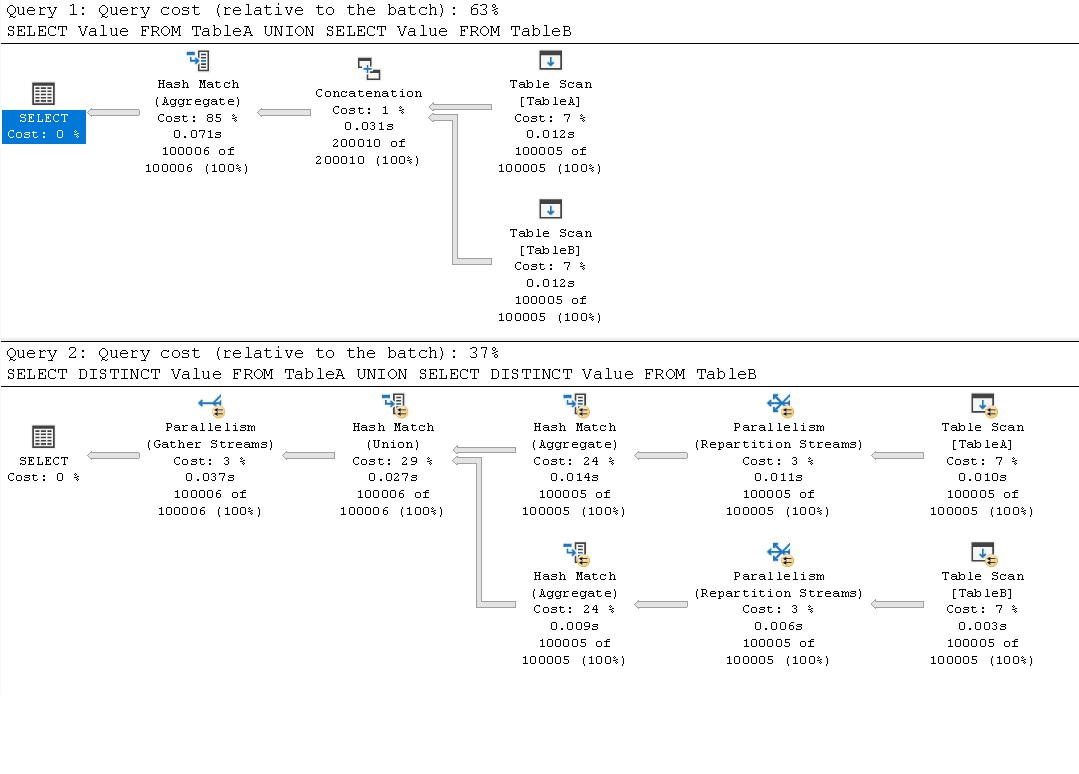
While the computed cost of the second query shows up as less, the execution of the query takes about the same time in each case, with the proper version taking the lesser time and simpler plan.
In the larger, unordered sets, the plan has changed to somewhat less optimum plans. The main difference in the plan without DISTINCT is that instead of a Distinct Sort (Sort) operator, it uses an Aggregate (Hash Match) operator. This is more efficient in larger sets than sorting data that will not need to be presented sorted.
On the second query, you now end up with two Aggregate (Hash Match) operators to remove the duplicated data, and then, since that data is not sorted, it uses a Union Hash Match operator (which would not need to consider that there are duplicated rows like the Aggregate one would).
In the amount of time taken, on my very small data set sizes (simple integer data doesn’t use a tremendous amount of space/memory), the no DISTINCT version was a decent bit faster. Times varied a bit, but the UNION version was consistently faster, even when the plan claimed to be faster with the parallelim.
|
1 2 3 4 5 6 7 |
--NO DISTINCT SQL Server Execution Times: CPU time = 157 ms, elapsed time = 921 ms. --WITH DISTINCT SQL Server Execution Times: CPU time = 218 ms, elapsed time = 1356 ms. |
So around 50% faster, even if that is just over .4 seconds.
Interestingly, the number of logical reads in my example turned out to be exactly the same. The output from STATISTICS IO were exactly the same:
|
1 2 3 4 |
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. Table 'TableB'. Scan count 1, logical reads 161, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. Table 'TableA'. Scan count 1, logical reads 161, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. |
A variation
Lastly, let’s look at one additional way you could write this. Using a UNION ALL operator, and then using DISTINCT to eliminate duplicates (just for comparison, using UNION is still the better way unless you specifically need all the rows for processing before outputting DISTINCT rows:
|
1 2 3 4 5 6 7 8 9 10 |
SET STATISTICS IO,TIME ON; WITH BaseRows AS ( SELECT Value FROM TableA UNION ALL SELECT Value FROM TableB) SELECT DISTINCT Value FROM BaseRows SET STATISTICS IO, TIME OFF; |
You should get the same 100006 rows output as in the previous section. The plan will more than likely be the exact same as for the UNION version of the query (since in this case you are specifically asking for the data to be concatenated and then deduped. Now this may not always be the case, with more complicated sets since the optimizer can refactor your query as needed. But suffice it to say that the output should be exactly the same.
The point is, plus a tangent
UNION does DISTINCT for you.
No matter if the data is distinct or not in the sets you are applying the UNION operator to, it will remove duplicates. However, be careful to understand that for UNION ALL, you may actually want to do a DISTINCT on the inputs if you want to not have duplicates in one side of the object.
For example:
|
1 2 3 |
TRUNCATE TABLE TableA; TRUNCATE TABLE TableB; INSERT INTO TableA VALUES(1),(1),(2) INSERT INTO TableB VALUES (2),(3),(3); |
If you want to get all of the data in both tables, but you need to remove duplicates on one side of the query, you can do this:
|
1 2 3 4 5 6 |
SELECT Value FROM TableA UNION ALL SELECT Value FROM TableB ORDER BY Value; --added for clarity |
The output of this looks kind of like what you would expect for two exact sets:
|
1 2 3 4 5 6 7 8 |
Value ----------- 1 1 2 2 3 3 |
But, it is fine to do this, if you really need it:
|
1 2 3 4 5 6 |
SELECT DISTINCT Value FROM TableA UNION ALL SELECT DISTINCT Value FROM TableB ORDER BY Value; --added for clarity |
Now the output shows DISTINCT values from one set, combined with a UNION:
|
1 2 3 4 5 6 7 |
Value ----------- 1 2 2 3 3 |
As always, requirements matter and if you need to do what seems like weird operations, they may be needed. The second point I want to make here is that when code smells funny, you need to doublecheck you are correct.
Appendix:
These are the tables that are used in the article. Nothing too complex!
|
1 2 3 4 5 6 7 8 9 10 11 |
USE TempDB; GO --note: no keys because this data may simulate any two sets of data CREATE TABLE TableA ( Value int ); CREATE TABLE TableB ( Value int ); |
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments